Hi.
We're Brand New Box.
We make
digital products
for the web.

You didn't set out to manage software.
But we did. We're a digital product studio: we work with clients like you to build new tech solutions. You've got unique business problems, and we can solve them.
Need a big, powerful platform? Need a small, sharp tool?
When our clients can't find an off-the-shelf tool that solves their problem, they call us. Odds are good we can help you, too.
Work.
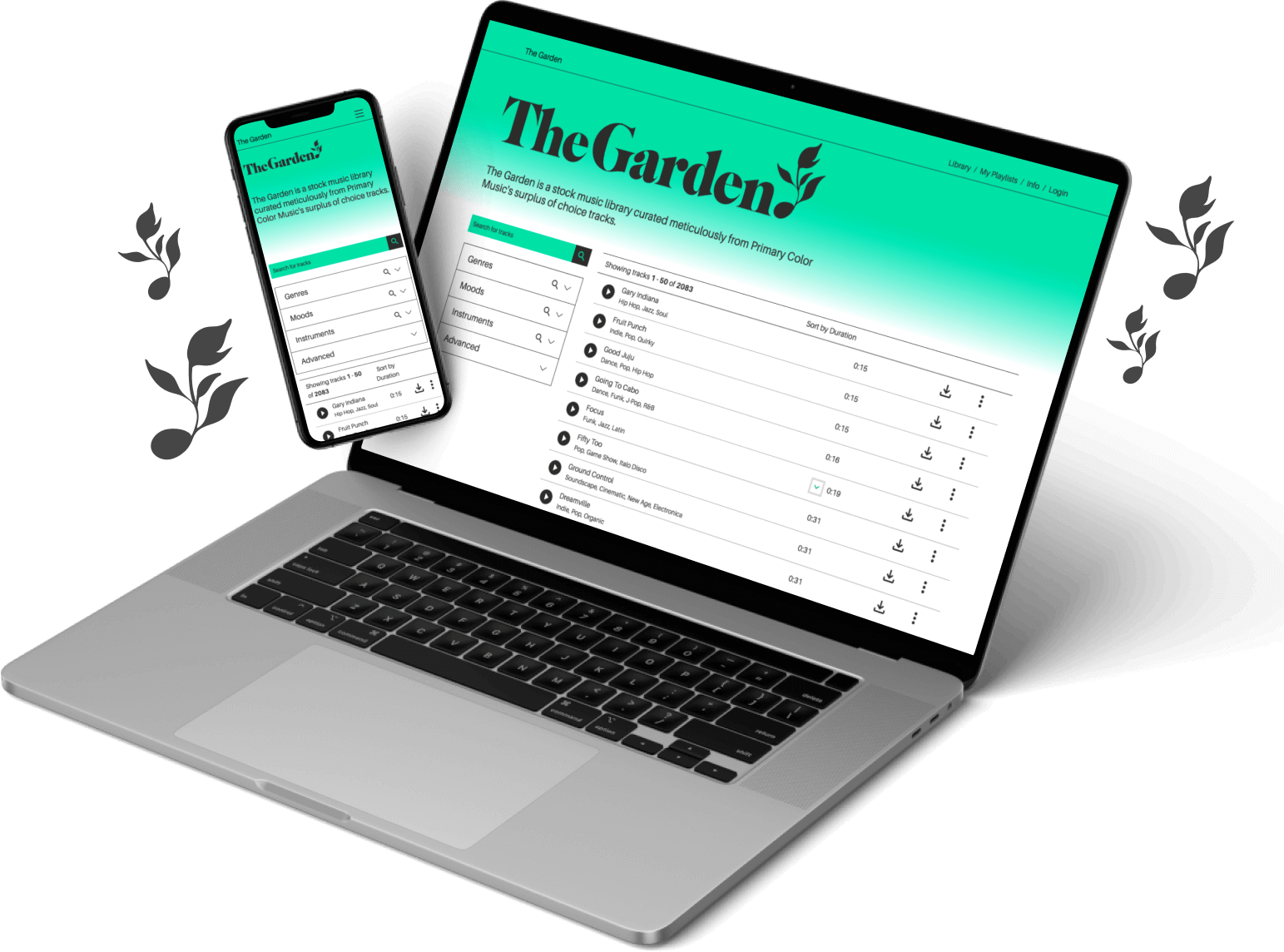
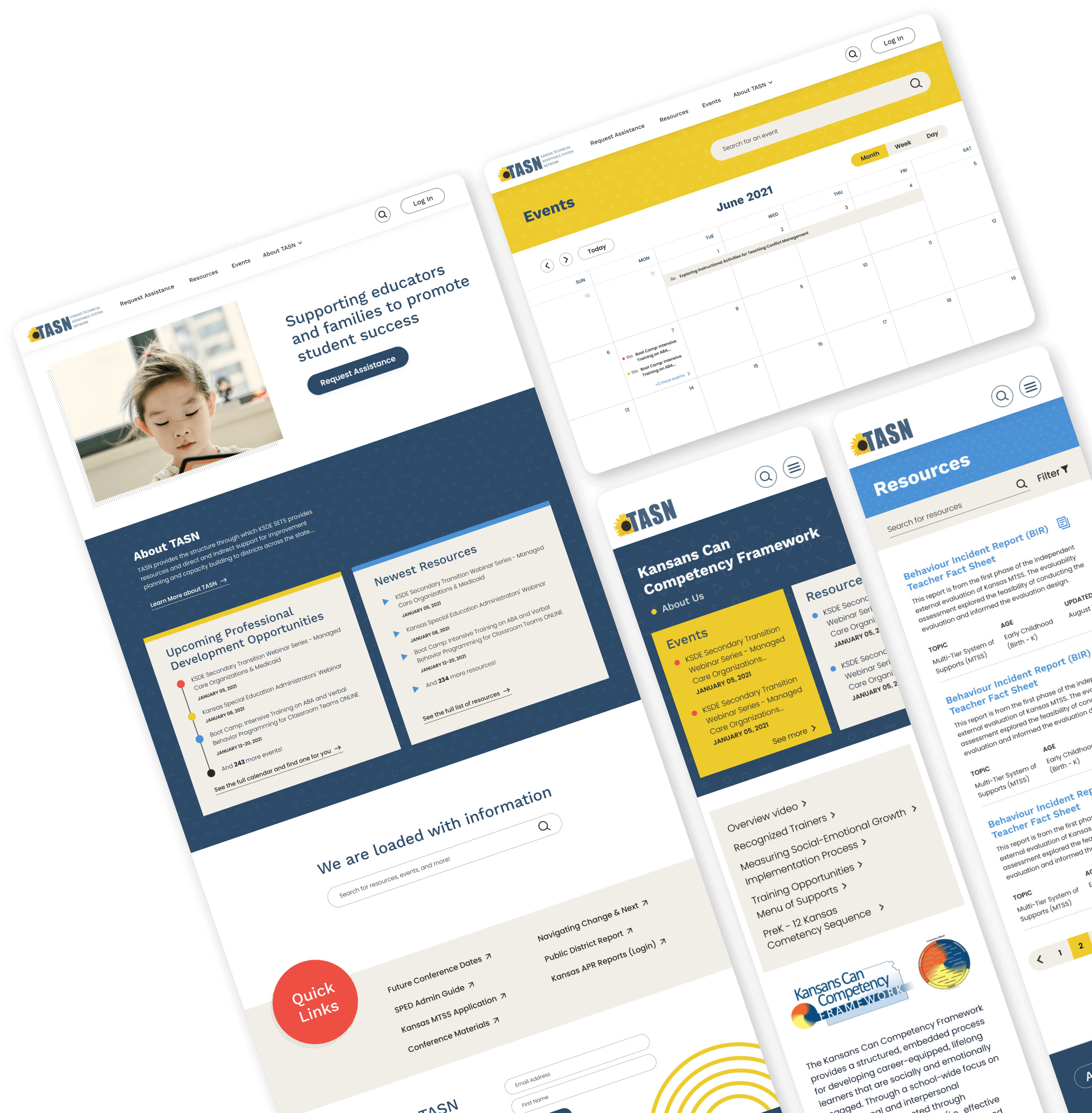
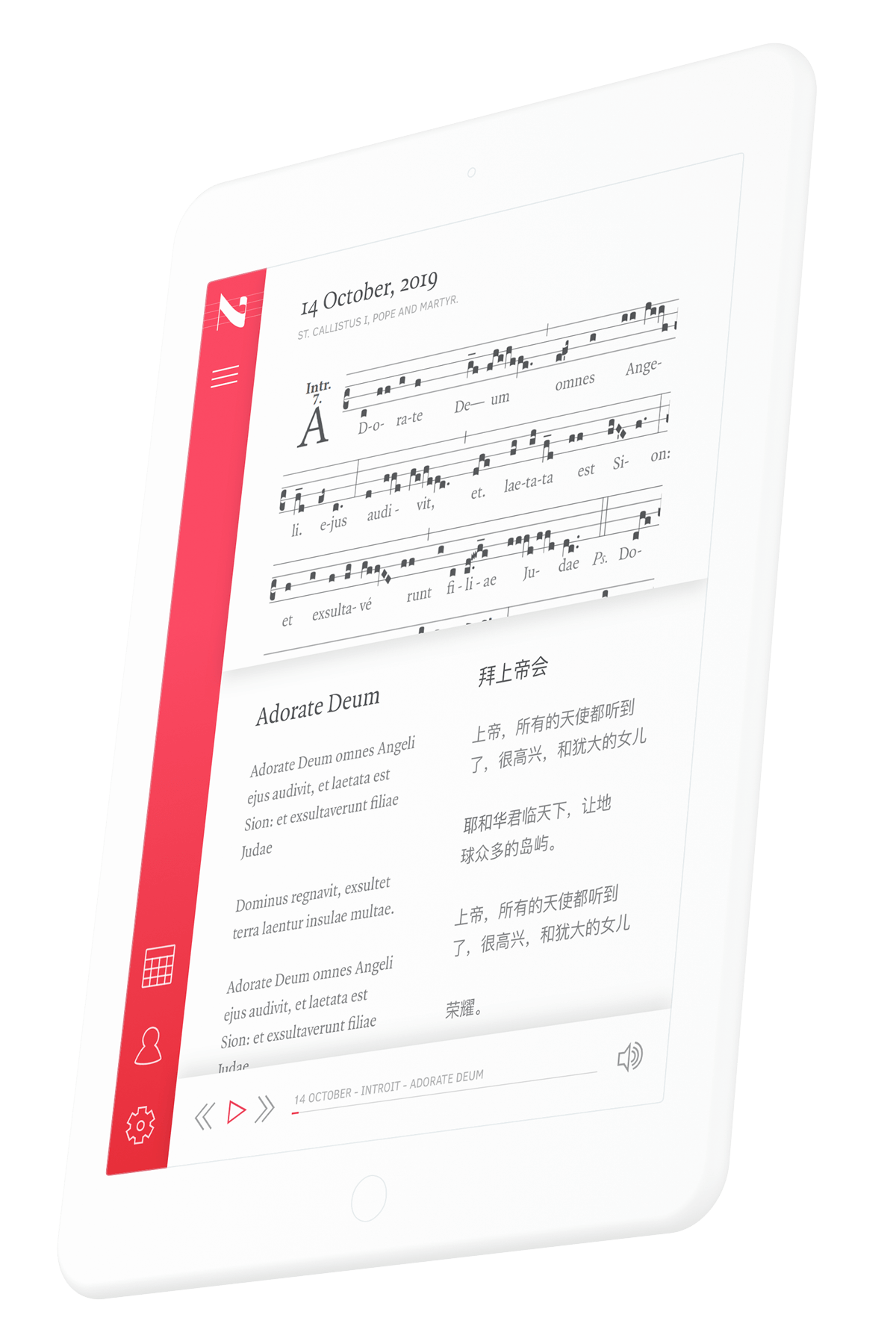
The proof is in the pudding. Here's a look at recent work, or you can see even more examples here .

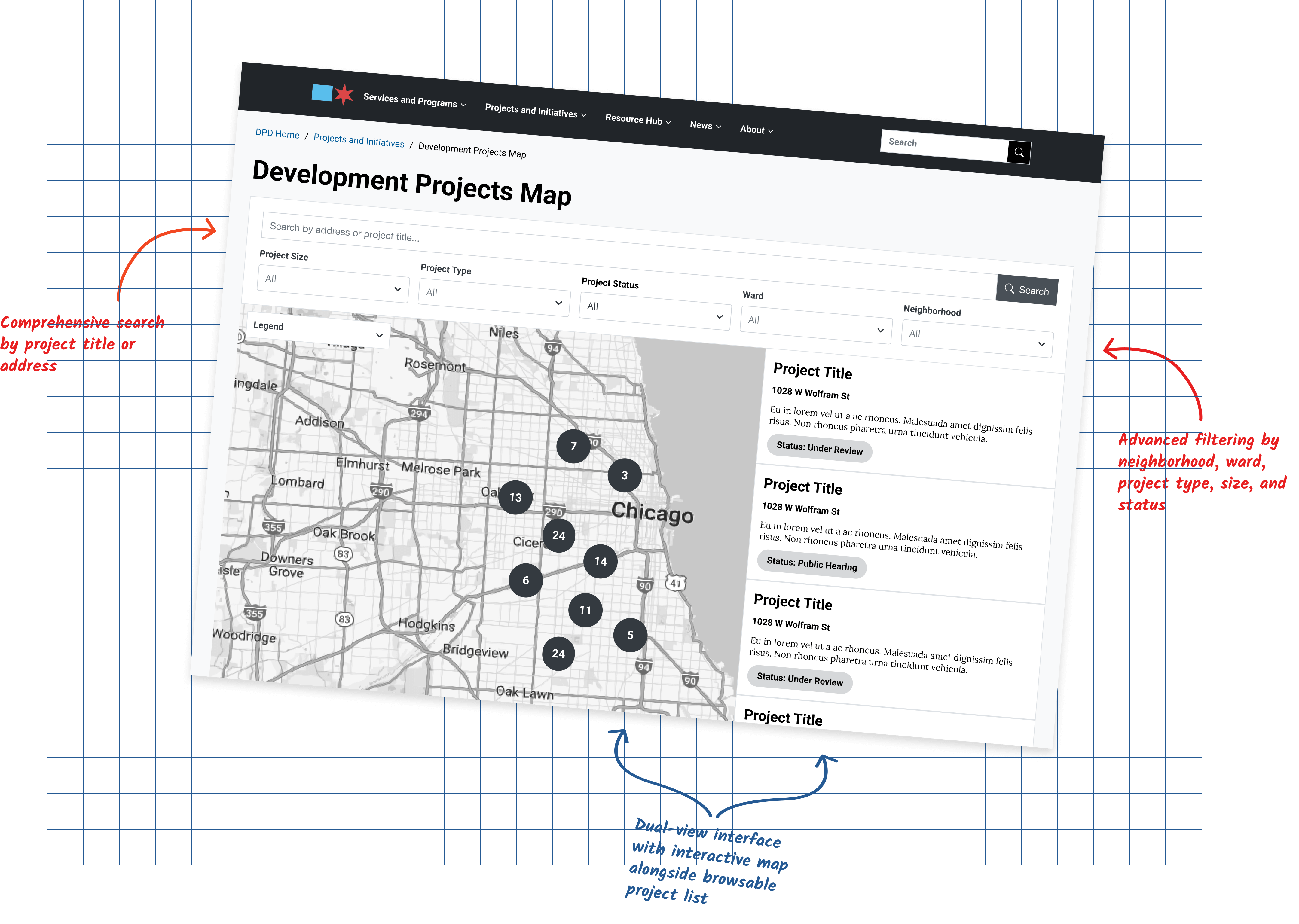
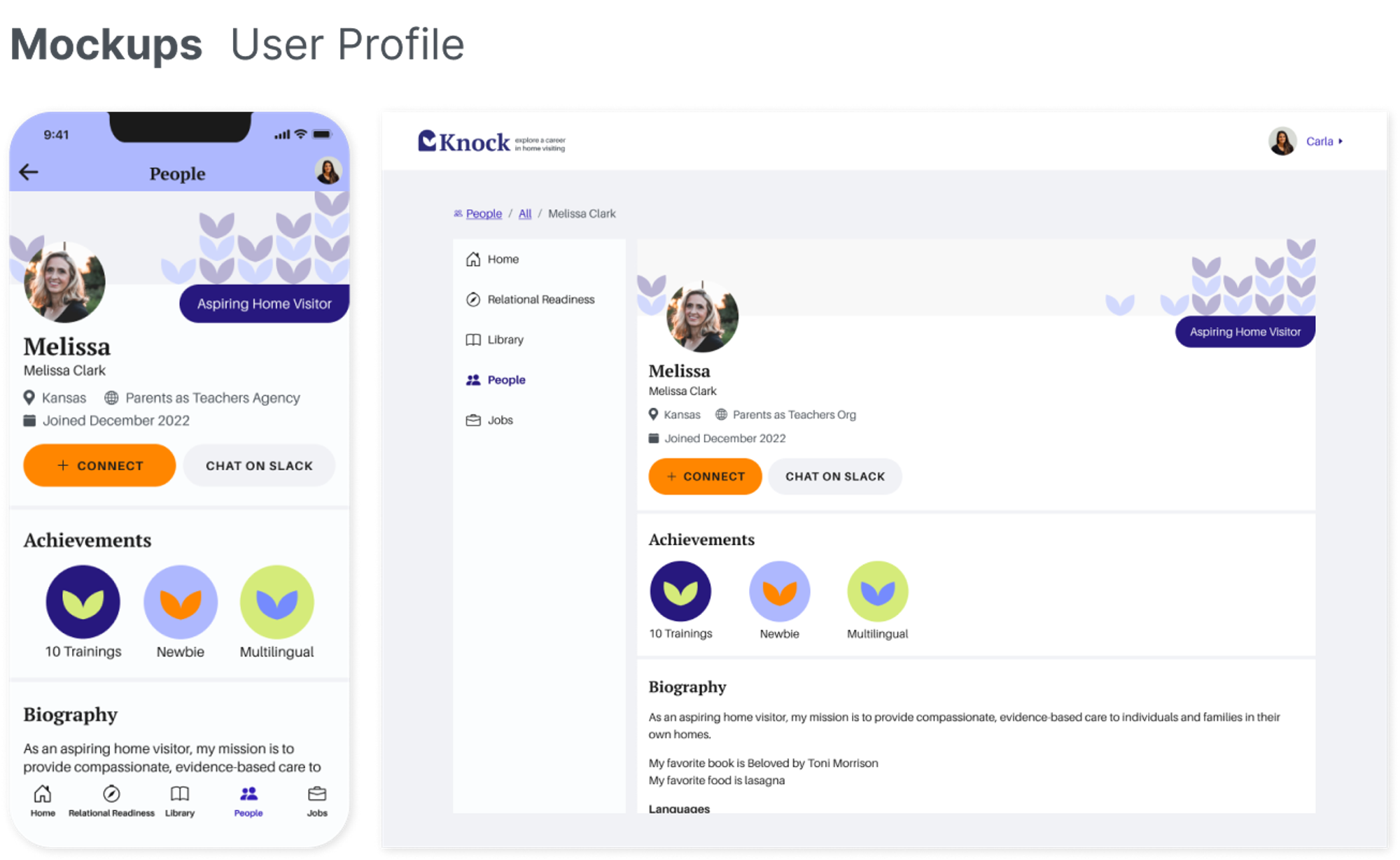
Professional Development Platform for Aspiring Home Visitors
Knock
Accessible from the Start: Building a Platform for Aspiring Home Visitors

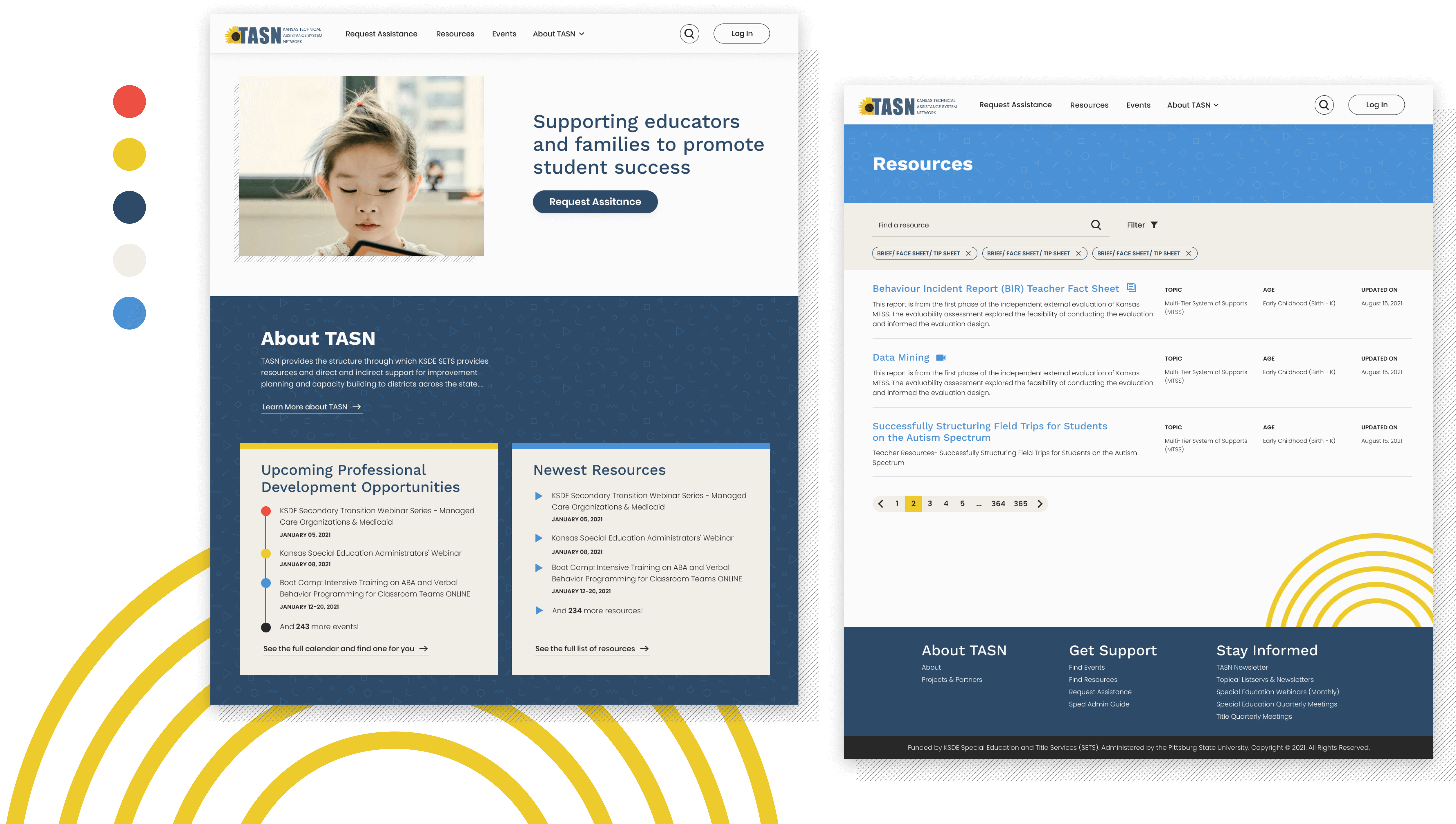
My Virtual Community Resource Map
MyVCRM
A new mapping platform to help young people navigate the real world.
Need to see more? There's more.








Notes
Keep it light.